

dataset & marketplace20 octobre 2025Depuis quelques posts, Botscorner s’attache à présenter des datasets dans ses botservatoires.
Ces datasets présentent un intérêt majeur : ils permettent, parfois à titre gracieux, d’accéder à des bases de données enrichies et standardisées. Plutôt que d’aller négocier des accords dispendieux avec les éditeurs ou leurs représentants, ces bases sont des marketplaces prisées.
cestquilepatron.com screenshot
Pourquoi acheter ses datas auprès des marketplaces plutôt qu’auprès des éditeurs ?
– Même quand le dataset affiche un user agent qui l’identifie sur toutes ses sessions, même quand le dataset a signé un accord avec un éditeur ou son ayant-droit, le client utilisateur final de la base est mécaniquement anonymisé. Que prévoit le contrat qui lie la marketplace à son client?
– la base est multi-titres, le contenus est frais, le format est standardisé, les contenus peuvent être enrichis, le guichet est unique, le tarif est très bas, le risque d’un audit sur les utilisations très éloigné.
-quand ces bases sont gratuites, les données sont alors partagées « for good » (la recherche). Vous pouvez néanmoins faire un don défiscalisé (ex: commoncrawl). Un don au dataset, pas à l’éditeur.
-certaines bases se constituent sur la base de recherches universitaires . Mais de ces recherches publiques peuvent sortir des entreprises privées. Par exemple, EventRegistry est une spin-off du Jožef Stefan Institute . C’est désormais une entreprise indépendante qui édite Newsapi.ai .
-Quand ces bases sont payantes, le tarif est compétitif. Quelle est la part de rémunération des éditeurs dans le prix à l’article proposé par ces quelques datasets ?
voici une revue des pages de tarifs de quelques unes de ces marketplaces:
newsapi.ai
diffbot.com
brightdata.com/
zyte.com
archive.org (free, open for donation)
Commoncrawl.org (free, open for donation)
Opoint.com (non publié sur le site, mais a signé avec le CFC)
webz.io (des datas gratuits Webhose et des datas payants, tarif non publié sur le site, mais a signé avec le CFC)
etc.
-parfois adossées à des services de proxies tournants (ips jetables, bypass captchas), sur lesquels on pose des scrapers de contenus, le client ne paie que le contenu effectivement collecté.
Moralité : si l’éditeur ou son mandataire n’est pas co-contractant, la marketplace va être tenté de privilégier la fluidité d’un accord technique très peu rémunérateur pour l’éditeur. [...]Lire la suite…

The Botservatory , n°19 – Supabase , dataset9 octobre 2025previous botservatories
Every day, hundreds of crawlers collect data from the websites of radio, TV, online, and print publishers. They perform monitoring, analysis, and summaries, providing the high-quality big data essential to AI.
Supabase, an open source alternative to Firebase : “Build in a weekend. Scale to millions. Supabase is the Postgres development platform. Start your project with a Postgres Database, Authentication, instant APIs, and realtime subscriptions”.
You can plug your Supabase project on digital assistants like N8n or Loveable, they will handle repetitive tasks (such as scraping external datas).
An example below with N8N.io:
obey robots.txt : As each project is independent, robots.txt may or may not be consulted depending on the project manager
2. Stats on Botscorner (on french publishers/weekly)
Supabase has 135 employees, 21M$ revenues , 398M$ fundings, estimation: 2B$ (progressing). [...]Lire la suite…

The Botservatory , n°18 – DataforSEO , dataset11 septembre 2025Every day, hundreds of crawlers collect data from the websites of radio, TV, online, and print publishers. They perform monitoring, analysis, and summaries, providing the high-quality big data essential to AI.
previous botservatories
Data for SEO , is a for-profit Organization, with desks in Estonia and Ukraine.
It was founded in 2016 by Nick Chernets: Founder and CEO, with this object:
“Powerful API Stack For Data-Driven Marketers : We provide comprehensive SEO and digital marketing data solutions via API. Our vision is to be a leader in data-driven marketing by leveraging data to equip businesses with the tools they need to create efficient and effective SEO strategies. Data is the new oil, and we are committed to providing the highest-quality fuel to power our clients’ SEO tools”
DataforSEO offers services linked to SEO , but not only. Once the contents are collected, there is a huge database ready to be monetized:
Data for AI training (The DataForSEO AI Optimization API equips you with access to keyword data enriched with search volume metrics)
“Our custom data collection services are designed to be the ultimate solution for all your AI initiatives. Whether you’re developing a new algorithm, refining an existing machine-learning model, or looking to expand your training dataset, we can deliver high-quality data at the scale your project requires to succeed”.
Content generation (DataForSEO Content Generation API is designed to facilitate the process of content creation. Its NLP model is capable of generating unique paragraphs of text, paraphrasing content, detecting grammar mistakes, and more.)
Content analysis : “Content Analysis API is a scalable solution for discovering citations of target keywords or brand names and analyzing relevant sentiments”.
DataForSEO : Costumers and prices:
obey robots.txt : looks for robots.txt. Only one French publisher mentionned “dataforseo” disallowed this 9-11, 2025 (but DataforSeo scraps anyway). The UAs are: RSiteAuditor and DataForSeoBot/1.0
Stats on Botscorner from 2022 (on french publishers/monthly)
DataforSEO stats show a huge activity on french websites plugged on Botscorner : more than +220.000 pages / 24h.
DataforSEO has 29 employees, for a 3+M$ 2025 revenue [...]Lire la suite…

The Botservatory , n°17 – Allenai.org/olmo , open LLM & dataset2 juillet 2025previous botservatories
Every day, hundreds of crawlers collect data from the websites of radio, TV, online, and print publishers. They perform monitoring, analysis, and summaries, providing the high-quality big data essential to AI.
The Allen Institute for Artificial Intelligence (AI2), LLM and open dataset for AI
The Allen Institute, as CommonCrawl, is a non-profit Organization.
It was founded in 2014 by Paul Allen, philanthropist and Microsoft co-founder, to find transformative ways to develop AI. As a non-profit AI research institute, AI2 develops foundational AI research and innovation to deliver real-world impact through large-scale open models, data, robotics, conservation, and beyond.
Among other projects, AI2 developped LLMs such as OLMo, Tülu, provides datasets available on Hugging Face
OLMo 2, the best fully open language model to date, including a family of 7B, 13B, and 32B models trained up to 6T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B.
AI2 partners with Gates Foundation, University of Washington and NAIRR and 500+ academic journals on Semantic Scholar project
obéir à robots.txt : on ne voit pas AI2 consulter robots.txt
Stats sur Botscorner.
AI2 Olmo’s stats show a huge activity on french websites plugged on Botscorner : more than +210.000 pages / 24h.
3. Estimated revenue $35M per year / 325 employees (source: Growjo) [...]Lire la suite…
ils nous font confiance10 juin 2025Botscorner provides B2B information on bots (media monitoring, artificial intelligence, SEO, RSS, etc.) allowing B2B syndication and subscription services of titles to regulate access to its copyrighted content and sign contracts.
France
https://www.lemonde.fr/
https://www.lefigaro.fr/
https://www.leparisien.fr/
https://www.ouest-france.fr/
https://www.lepoint.fr/
https://www.prismamedia.com/
https://www.challenges.fr/
https://www.sciencesetavenir.fr/
https://www.infopro-digital.com
https://1health.fr/
https://www.editions-lva.fr/
Germany
https://www.faz.net/aktuell/
Canada
https://www.lapresse.ca/
https://www.ledevoir.com/
Rights collection and distribution company
https://www.copibec.ca/ [...]Lire la suite…

Le Botservatoire , le bulletin des crawlers commerciaux, n°16 – Brightdata.com10 avril 2025Portrait-Robot de Brightdata.com, dataset for AI & media monitoring
Les précédents botservatoires
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs radio, TV, presse online & print. Ils opèrent pour les activités de veille, des analyses, des résumés, fournissent le big data de qualité indispensable aux IA …
Portrait-Robot de Brightdata (dataset for AI, media monitoring)
Brightdata propose de très nombreux services, notamment:
-les proxies tournants (qui permettent de multiplier les ips locales temporaires),
-le scraping de contenus
-les apis d’accès à des datasets…
Brightdata nous garantit un scraping « éthique » grâce à son Brightbot, qui respecte un fichier « collector.txt » , une sorte de robots.txt dédié à ce type de scraping ( ?). Brightbot monitore les sites scrapés pour adapter son activité à la charge supportable par les sites ciblés.
Dans la foulée, Brightdata.com détaille son scraping éthique, mais sans Brightbot cette fois, avec
-des user agents de navigateurs identifiés comme des internautes
–des proxies rotatifs, de fausses pages de provenance, de résolutions de captchas… toutes solutions permettant de collecter les datas nécessaires aux usages B2B, dans un strict cadre de « data for good »
“Data is the fuel that drives AI innovation, and at The Bright Initiative, Bright Data’s data-for-good program, we are committed to harnessing AI’s potential for positive change. Through strategic partnerships, research support, and ethical data access, we empower our partners to create meaningful social impact.
The Bright Initiative provides pro-bono access to Bright Data’s industry-leading data collection technology and datasets to nonprofit organizations, academic institutions, researchers, and public bodies working in the AI for Good space.”
Le scrap peut se faire via IA :
Brightdata annonce plus de 20.000 clients, Chiffre d’affaires estimé : $220.1M per year, 1084 Employees (+30%)
obéir à robots.txt : on ne voit pas Brightdata consulter robots.txt
Stats sur Botscorner: Les stats Brightdata montrent une activité conséquente sur les sites (France) équipés de Botscorner : jusqu’à 50.000 pages sur une journée. [...]Lire la suite…

Le Botservatoire , le bulletin des crawlers commerciaux, n°15 – ZYTE.com3 mars 2025Portrait-Robot de Zyte.com
Les précédents botservatoires
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs radio, TV, presse online & print. Ils opèrent pour les activités de veille, des analyses, des résumés, fournissent le big data de qualité indispensable aux IA …
Portrait-Robot de ZYTE.com, “the best place to host Scrapy spiders”
Sur son site, Zyte propose un service « News & Article data : Accurate articles and news data from global publishers and the largest news websites in the world”.
Zyte démontre sa bonne connaissance des sites de news : « Articles and news data comes in all shapes and sizes. We get it all”.
1-“Mainstream broadcast : These are large organizations that have dominated the news world for many years. They include TV networks, newspapers, press releases, and radio stations that are widely recognized and trusted by the public”.
2-“Industry and vertical : These websites focus on specific industries or niches, providing news and information that is relevant to professionals in those fields”.
3-“Alternative media and independents : These websites operate outside of the traditional, corporate-owned media landscape. They may provide alternative perspectives on news and events”.
4-“Groups, individuals, and influencer : These web pages are created and run by individuals or groups, such as bloggers, vloggers, or podcasters”.
5-“Online aggregators : These websites collect and curate crucial news data from various sources and present them to users in a single location”.
6-“News blogs : These websites are dedicated to latest news articles and opinion, often with a specific focus or niche”.
7-“Video news : Video news websites provide news coverage through video content, which can be more difficult to collect and parse data from than text-based news”.
8-“Social media : Social media platforms where journalists and publications source stories and where many brands self-publish and promote their content”.
À quoi servira ce scraping ?
“Brand monitoring & reputation management , Market research , Content optimization (SEO) , News aggregation , Tackling misinformation , Building AI models and algorithms , Creating dashboards , Ad and affiliate tracking”.
La factorisation du scrap donne un prix de service assez intéressant, que ce soit pour gérer son scraping ou pour l’acquisition de données déjà extraites et mises en forme.
On notera que IPXO, une place de marché pour louer des adresses IPs, se présente comme « un partenaire de confiance en matière de location d’IPs pour les entreprises dans plus de 75 secteurs d’activité », et avance quelques services partenaires dont « Zyte ».
D’ailleurs, parmi les différents usages possibles des ips de location, on peut trouver le « data crawling and data extraction » :
“With the support of professional IP leasing services provided by IPXO, a leading web exfiltration company in Europe can continue introducing innovations and improving the quality of services to guarantee quick and efficient data crawling and data extraction”.
2. Estimated Revenue, Valuation, employee data
IPXO.com estimated annual revenue is currently 8M$ per year.
Employee : 62
Zyte (ScrapingHub) estimated annual revenue is currently 27M$ per year.
Employee : 171
3. stats on Botscorner [...]Lire la suite…
Le Botservatoire , le bulletin des crawlers commerciaux, n°14 – Timpi.io dataset10 décembre 2024Portrait-Robot de Timpi.io, dataset for AI & media monitoring
Les précédents botservatoires
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs radio, TV, presse online & print. Ils opèrent pour les activités de veille, des analyses, des résumés, fournissent le big data de qualité indispensable aux IA …
Timpi.io nous propose de participer à la démocratisation de l’information mondiale (et de gagner des récompenses). L’index Web de Timpi repose sur un réseau décentralisé de nœuds gérés par des utilisateurs indépendants.
« Giving you the power of data » : Nos (sic) données sont utilisées pour développer des applications et informer les entreprises. Par exemple, l’entraînement de l’IA : Utilisez de vastes ensembles de données pour entraîner vos modèles d’IA avec des informations diverses et complètes provenant du Web, améliorant ainsi la précision et les performances.
Le moteur de recherche Timpi, enrichi par Wilson (l’IA de Timpi), s’appuie sur un modèle de gouvernance décentralisé. Timpi utilise une technologie « DePIN » (Decentralized physical infrastructure network)
Les DePINs sont le pont entre les mondes physique et numérique. Ils utilisent des blockchains et offrent des récompenses sous forme de jetons pour les services enregistrés publiquement. Les DePINs créent un réseau pour les objets physiques, tels que le Wi-Fi et le stockage de données, permettant aux gens de partager leurs ressources directement avec d’autres utilisateurs sans avoir besoin d’un intermédiaire.
cointelegraph.com
Timpi propose l’accès au plus grand ensemble de données au monde avec plus de 5 milliards de pages Web.
Wilson AI les versions futures de WilsonAI offriront encore plus d’informations en temps réel, de personnalisation pour les utilisateurs
1. obéir à robots.txt les ips de Timpi ne passent pas sur robots.txt.
2. Stats sur Botscorner.
Les stats Timpi montrent une activité conséquente sur certains sites équipés de Botscorner. Deux exemples ci-dessous de scraps Timpi sur des sites de presse, dans deux pays différents (jusqu’à 160.000 pages sur une journée sur un site) [...]Lire la suite…

Botscorner : l’innovation au service de la protection des contenus et des données26 novembre 2024interview publiée sur le site du GESTE
Yan Gilbert était le Directeur de la diffusion numérique du groupe Nouvel Observateur de 2000 à 2015. Il a ensuite dirigé le GIE Panorama de Presse de 2010 à 2015. Depuis 2017, il occupe la fonction de Directeur Général au sein de Clipeum, éditeur de la solution innovante Botscorner.
Pouvez-vous nous expliquer le fonctionnement de Botscorner ?
Botscorner analyse le trafic des robots et des proxies sur les sites de presse. L’éditeur envoie automatiquement ses logs de sessions, qui sont enrichis par Botscorner, grâce aux milliers d’informations accumulées et mises à jour depuis son lancement en 2017.
-Les visites « internautes » ne sont ni enrichies ni suivies.
-Les sessions « robots » sont enrichies et classées par typologie de marché. Cela permet de suivre distinctement les bots par activité et par modèle économique : Searchbots, AI, datasets, media monitoring, sites parasites, gestionnaires RSS, SEO, régie pub… Ces activités sont monétisables.
–Les sessions « proxies » émanant d’entreprises, d’associations, d’administrations, d’universités… sont également renseignées, éventuellement avec les infos « paywall », afin que l’éditeur puisse adresser des prospects ou de comparer les infos avec ses données « grands comptes ».
Comment cette technologie permet-elle d’identifier et de réguler les robots accédant aux contenus protégés par le droit d’auteur ?
Cela dépend des sites, mais on observe généralement qu’une moitié des demandes de pages sur les sites de presse ne sont pas effectuées par des internautes mais par des programmes (IA, mediamonitoring, datasets, searchbots, SEO, …). Botscorner conjugue différents moyens pour identifier les bots, comme le ferait une Bot Mitigation (identification technique bots/humains et réponse en temps réel). La finalité de Botscorner n’est pas de traiter des questions de sécurité (DDos, SQL injection, etc.) mais d’identifier les actions automatiques et de renseigner le trafic B2B. Identifier la personne morale renseigne sur le modèle économique. Cela permet de comprendre à quoi vont servir les données récoltées : comment le « propriétaire » des robots en tire parti pour son service. Ces informations pour action, remontées par Botscorner, concernent différents services de l’éditeur. En effet, Botscorner n’agit pas en « coupure » comme le ferait une bot mitigation. La régulation reste dans la main de l’éditeur, qui va décider du traitement approprié, en fonction de sa stratégie, service par service. Par exemple : blocage de crawls anonymes par le service technique, recueil de preuves par le service juridique, négociation par le service syndication.
Botscorner a annoncé 2 partenariats importants (Le Monde et Ouest France). Pouvez-vous nous expliquer en quoi consistent ces partenariats et quels bénéfices les éditeurs vont-ils pouvoir en tirer ?
Et nous allons bientôt annoncer d’autres partenariats !
Je ne peux pas m’exprimer à la place des clients de Borscorner. Tout dépend de leur stratégie. Chaque éditeur a des utilisations assez différentes des informations remontées. En fonction de l’approche de chacun, ces informations intéressent les services syndication, business dev, abonnements grands comptes, juridique, technique… Botscorner remonte les informations sur les bots en fournissant aux services de l’éditeur :
–La fiche contacts de l’entreprise qui active le bot
–La nature du trafic (proxy ou bot)
–Le volume et la nature des données collectées (article, jpg)
–Les infos techniques qui permettent de bloquer les bots si la négociation s’enlise
Dès lors, certains éditeurs recourent à Botscorner uniquement pour identifier les crawlers indésirables sur leur base de données, en vue de les bloquer. En revanche, d’autres utilisent à plein toutes les informations présentées, en fléchant les proxies entreprises/administrations vers le service abonnements grands comptes, les crawlers B2B vers le licensing/business développement et les scrapers anonymes vers le service technique, entre autres.
Quelles synergies souhaitez-vous développer avec chacun d’eux ?
Des contacts réguliers se mettent en place, au début pour se former sur l’outil, puis pour faire le point sur l’activité des bots, lever des interrogations sur certains crawlers, etc. Généralement, les sessions hebdomadaires ou bimensuelles durent d’une demi-heure à une heure. Même si cela concerne généralement les services commerciaux, nous avons aussi des échanges avec les services techniques et juridiques.
Quelles sont les mesures de protection des données que Botscorner met en place pour garantir la confidentialité des informations collectées lors de l’identification des robots ?
La protection des données est cruciale. Nous ne transmettons aucune donnée à des tiers autre que l’éditeur lui-même, qui nous a fourni ses logs pour analyse. Et, sur son dashboard, l’éditeur accède uniquement aux informations concernant ses propres titres. Par ailleurs, nous avons assuré notre mise en conformité au RGPD, le règlement européen sur la protection des données, avec l’aide d’un cabinet spécialisé. La durée de conservation des données envoyées par les éditeurs est limitée : nous supprimons tous les informations après 24h.
Quels sont les principaux défis actuels rencontrés par Botscorner ? Droits voisins ?
Effectivement, la loi sur les droits voisins, mais aussi l’arrivée des IA grand public, ont entraîné beaucoup d’intérêt pour Botscorner. Pour nous, cela génère une adaptation permanente aux techniques de crawl, et une veille active sur toutes les utilisations des données et les nouveaux modèles économiques. Cela implique une mise à jour quotidienne de la cartographie globale des bots, et les remontées d’informations sur le marché B2B.
Quelles sont les prochaines étapes de Botscorner (en termes d’innovation et développement) pour répondre aux besoins futurs des éditeurs ?
Nous avons des clients dans plusieurs pays, sur deux continents. Grâce à leurs remarques et à leurs retours d’expérience, le service ne cesse de progresser ! Les prochaines étapes consistent à répondre toujours mieux aux attentes de nos clients, à améliorer le service grâce à leurs suggestions, et à continuer de nous développer, en France et à l’international.
Le Geste:
Depuis sa création en 1987, le GESTE s’est fait fort d’analyser les mutations du modèle économique des éditeurs de contenu et services en ligne afin de permettre une meilleure compréhension des enjeux posés par la transformation numérique et l’émergence de conditions économiques, législatives et concurrentielles. Aujourd’hui présidé par Bertrand Gié, Directeur délégué du pôle News du Groupe Figaro, le GESTE fédère une centaine d’éditeurs en ligne, tous horizons confondus : presse en ligne, médias digitaux et audiovisuels, plateformes de musique, services mobiles et vocaux… Le GESTE, lieu d’échanges et de veille permet à ses membres d’avoir un temps d’avance sur les débats qui font l’actualité et les positions législatives. Des solutions concrètes et applicables pour un réel développement économique y sont débattues avant d’être soumises au gouvernement et aux instances publiques. [...]Lire la suite…

Le Botservatoire , le bulletin des crawlers commerciaux, n°13 – NewsAPI.AI (dataset)17 octobre 2024Portrait-Robot de EventRegistry, maison mère de NEWSAPI.AI, dataset for AI & media monitoring
Les précédents botservatoires
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs radio, TV, presse online & print. Ils opèrent pour les activités de veille, des analyses, des résumés, fournissent le big data de qualité indispensable aux IA …
Portrait-Robot de NewsAPI.AI et EventRegistry.org (dataset for AI, media monitoring)
Forbes nous présente EventRegistry comme « un service de surveillance mondiale des médias en temps réel, grâce à des algorithmes de recherche multilingues et une extraction approfondie d’informations afin de transformer les données en une plateforme décisionnelle significative ».
Vous cherchez des bases d’articles de presse de qualité? Ne cherchez plus:
“ Get articles from 150,000 news publishers worldwide”“ Get the full news content as well as information about the mentioned entities, topics and sentiment.”
“Discover news content minutes after it is published”
“Archives since 2014”
“World’s leading companies are using NewsApi.ai”
Clients:
Spotify, IBM, Palantir, Bloomberg, Merck, Accenture, BASF, Johnson&Johnson, Airbus, Barclays, Disney, PWC, arabesque, OECD, BASF, McKinsey, Gouvernement Slovenie…
Eventregistery a obtenu des financements de la part du fonds Google’s Digital News Initiative.
Le Réseau académique et de recherche de Slovénie, Arnes, propose une présentation d’EventRegistry
1. obéir à robots.txt : EventRegistry utilisait un user agent explicite. Les quelques éditeurs qui le bloquaient ont peut-être eu raison de cet affichage ? Désormais, le user agent n’apparait plus, mais le trafic n’a pas baissé, au contraire. Ces ips ne passent de toutes façons pas sur robots.txt.
2. Stats sur Botscorner.
Les stats d’EventRegistry, dont le service a été lancé en 2017, montrent une activité conséquente sur les sites équipés de Botscorner.
3. Tarifs [...]Lire la suite…

Le Botservatoire , le bulletin des crawlers commerciaux, n°12 – Adata.pro9 octobre 2024Portrait-Robot de ADATA.PRO, une société multiservices (dataset for AI, media monitoring …)
Les précédents botservatoires
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs radio, TV, presse online & print. Ils opèrent pour les activités de veille, des analyses, des résumés, fournissent le big data de qualité indispensable aux IA …
ADATA.PRO, une société multiservices (dataset for AI, media monitoring …)
Parmi les très nombreux services offerts par Adata.pro, on peut trouver la rubrique « Data Solutions », présentée ainsi (extraits) :
Adata.pro is a trusted partner to data and content aggregators, financial and risk & compliance consultants, and PR agencies internationally.
We specialise in content, data and business intelligence services, media monitoring and analysis. Our suite of services spans Data Automation, Data Management, and Training Data for AI
Our data automation solutions collect data from various sources, such as databases, APIs, and web scraping.
Adata.pro est membre de UpData One Community une organisation qui regroupe des sociétés du secteur, et de FIBEP (the world’s media intelligence association).
Des fonds Européens aident A Data Pro à développer une technologie pour produire des articles de presse
1. obéir à robots.txt les ips de Adata.pro présentent un user agent d’internaute accédant au site avec un navigateur. L’éditeur ne peut donc marquer son désaccord avec ce scraping par ce biais. Ces ips ne verraient de toutes façons pas cette indication, puisqu’elles ne passent pas sur le fichier robots.txt.
2. Stats sur Botscorner.
Les stats Adata.pro, dont le service a été lancé en 1999, montrent une activité conséquente sur les sites équipés de Botscorner.
3. Estimated Revenue, Valuation, employee data
Adata.pro estimated annual revenue is currently 101-500M$ per year.
Employee : 352 (between 201-500 ) [...]Lire la suite…

Le Botservatoire, le bulletin des crawlers commerciaux, n°11 – Panalis.de19 septembre 2024Portrait-Robot de Panalis, une société de media monitoring spécialisée « Politique »
Les précédents botservatoires
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs radio, TV, presse online & print. Ils opèrent pour les activités de veille, des analyses, des résumés, fournissent le big data de qualité indispensable aux IA …
Panalis.de présente ainsi son service (extraits) :
PANALIS Solutions offre la réponse digitale à la gestion des affaires publiques, de la veille à l’analyse politique.
plus de 1 400 utilisateurs satisfaits au sein d’associations, d’entreprises, d’agences et de l’administration.
Suivi politique professionnel pour la France , l’UE , USA, Italie, Autriche
PANALIS Monitoring : La base de données PANALIS regroupe plus de 100 000 acteurs du monde politique, économique et social et, contient plus 100 millions de publications provenant de plus de 250 000 sources, offrant ainsi la plus grande base de données politique d’Europe.
Assistant vocal virtuel (Text-2-speech): Résumés et contenus des publications lus à haute voix
Niveaux d´informations :
Local, National : Institutions, organisations, entreprises, ONG, instituts de recherches, politiciens, experts et médias au niveau régional et national.
International : Des informations parlementaires provenant de plus de 50 pays à travers le monde, institutions et organisations internationales
1. obéir à robots.txt les ips de Panalis.eu ne passent pas sur robots.txt. Il serait difficile pour un éditeur de mentionner son désaccord avec ce crawl, car au moment où l’on écrit ces lignes, Panalis n’a pas encore rédigé une page de renseignements sur le user agent affiché par son crawler. Il semble plutôt utiliser des user agents génériques (PHP, Java, etc.) :
Proprietary crawler technologies make PANALIS fast, versatile, robust and independent of third-party providers. The diverse data source categories include: Databases, Interfaces to real-time information sources, Website article, Social media, Online media
2. Stats sur Botscorner.
Les stats Panalis.de, dont le service a été lancé en 2015, montrent une activité conséquente sur les sites équipés de Botscorner, avec jusqu’à 145K requêtes, 50K pages par jour, tous types d’éditeurs. des blocages par moments peuvent gener le crawl par moments.
3. Estimated Revenue, Valuation, employee data
PANALIS Solutions GmbH’s estimated annual revenue is currently $1.1M per year. [...]Lire la suite…
Le Botservatoire , le bulletin des crawlers commerciaux, n°10 – TheHive.AI10 août 2024Portrait-Robot de TheHive.ai, un service IA B2B
Les précédents botservatoires
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs radio, TV, presse online & print. Ils opèrent pour les activités de veille, des analyses, des résumés, fournissent le big data de qualité indispensable aux IA …
TheHive.ai présente ainsi un éventail de services allant de la génération de contenus multimedia à la modération, en passant par le suivi de la présence des marques et logos dans les medias, la recherche de plagiats
Solutions for moderating content of all forms;
AI to understand, search, and generate content (videos, texts, images) using prompts.
AutoML: Quickly develop and deploy custom models with limited training data. Generate multimodal conversations through natural language prompts
Sports, Media, & Marketing. Solutions for measuring sponsorships, monitoring cross-platform advertising, and unlocking premium ad inventory.
image Match & Similarity: Find exact and similar matches across the open web or a custom index
quelques clients de TheHive.ai
1. obéir à robots.txt TheHive.ai passe bien sur le fichier robots.txt.
Il est néanmoins difficile pour un éditeur de mentionner son désaccord avec ce crawl, car au moment où l’on écrit ces lignes, TheHive.ai n’a pas encore rédigé une page de renseignements sur le user agent affiché par son crawler (nous ne l’avons pas trouvée?).
TheHive utilise un crawler : Mozilla/5.0 (compatible; ImagesiftBot; +imagesift.com)
2. Stats sur Botscorner.
Les stats de thehive.ai, dont le service a été lancé en 2013, montrent une activité conséquente sur les sites équipés de Botscorner: jusqu’à 550 000 requêtes, 380 000 photos et 240 000 pages demandées par jour, sur tous types d’éditeurs.
3. Estimated Revenue, Valuation, employee data
theHive.ai’s estimated annual revenue is currently $156.2M per year
theHive.ai’s current valuation is $2B.
theHive.ai has 424 Employees
source Growjo [...]Lire la suite…

Le Botservatoire , le bulletin des crawlers commerciaux, n°09 – OpenAI Search8 août 2024Portrait Robot de openAI search, un moteur de recherches et de réponses.
Les précédents botservatoires
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs radio, TV, presse online & print. Ils opèrent pour les activités de veille, des analyses, des résumés, fournissent le big data de qualité indispensable aux IA …
D’OpenAI, on connaissait ChatGPT, qui s’est entrainé pendant des années sur divers datasets, le plus connu étant celui proposé gratuitement par CommonCrawl, et constitué notamment de contenus « presse ». On découvre depuis fin juillet 2024 un nouveau service en version Beta : OpenAI Search
OpenAI le décrit ainsi : « OAI-SearchBot is for search. OAI-SearchBot is used to link to and surface websites in search results in the SearchGPT prototype. It is not used to crawl content to train OpenAI’s generative AI foundation models.«
OpenAI Search lance donc un solide concurrent à Google. Contrairement à son concurrent, le service d’OpenAI ne serait pas basé sur des algorithmes de classement. OpenAI Search va utiliser l’intelligence artificielle pour fournir les réponses aux internautes. Il annonce tester déjà le modèle avec quelques éditeurs.
OAISearch affichera les sources ayant permis de formuler la réponse résumée donnée par OAISearch.
OAI Search ne donne aucune information sur le modèle économique proposé aux éditeurs pour générer ces résumés sur de l’information « temps réel », ni à ce stade sur le taux de clic observé sur les liens proposés en sidebar à côté de la réponse claire et concise de OAISearch.
Le volume déjà substantiel d’abonnés au service ChatGPT, et la dynamique du marché de l’IA plaident pour une étude attentive de cette beta version par les éditeurs de presse.
extrait du site OpenAI Search: « We’re testing SearchGPT, a prototype of new search features designed to combine the strength of our AI models with information from the web to give you fast and timely answers with clear and relevant sources. We’re launching to a small group of users and publishers to get feedback. While this prototype is temporary, we plan to integrate the best of these features directly into ChatGPT in the future. (…) Getting answers on the web can take a lot of effort, often requiring multiple attempts to get relevant results. We believe that by enhancing the conversational capabilities of our models with real-time information from the web, finding what you’re looking for can be faster and easier.”
1. obéir à robots.txt
OAI-Search passe sur robots.txt. OAI-S annonce suivre les recommandations de ce fichier, dans un délai de 24h.
Full user-agent string: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot
OAI Search passe sur la plupart des fichiers robots.txt des sites suivis par Botscorner, avant de crawler. Il passe peu sur ce fichier: 12 demandes de fichiers robots.txt, sur pluei
2. Stats sur Botscorner.
Les stats de OAI-Search, dont la version beta a été officiellement lancée fin juillet, commencent à apparaitre sur Botscorner, avec quelques milliers de pages par jour, tous types d’éditeurs.
OAI-S fait encore quelques réglages sur son crawl, on observe de nombreux refus d’accès à la page à cause de la méthode de crawl, qui se résorbent au fil du temps. en cette première semaine d’août 2024, on ne voit pas encore de mention « disallow » à destination du user agent d’OAI Search. [...]Lire la suite…

Le Botservatoire , le bulletin des crawlers commerciaux, n°08 – You.com31 octobre 2023Portrait Robot de You.com , un moteur de réponses et de création de contenus.
YOU.COM: « immediate answers, no more scrolling through a list of blue links”
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs radio, TV, presse online & print. Ils opèrent pour les activités de veille, des analyses, des résumés, fournissent le big data de qualité indispensable aux IA …
You.com est un moteur de réponses aussi simple dans sa présentation que peut l’être Google : un logo et une barre de recherches.
Le service a été créé en 2020 par l’ancien fondateur de MetaMind-IA, racheté par SalesForce. Il bénéficie d’une levée de fonds de 45M$, ses revenus sont actuellement estimés à 15M$/an.
Modèle économique :
Le service qui propose un “Chat GPT-4” service est gratuit dans une version de base non personnalisée, et devient payant (9,99$/mois) dès que l’on veut des réponses plus élaborées, ou créer des images, des résumés,…
Comme Google, il propose aux annonceurs des espaces publicitaires, sous forme d’annonces privées
comportement
-obéir à robots.txt : You.com passe sur robots.txt, mais ce service utilisant ChatGPT peut passer sur des sites qui ont interdit GPTbot.
–Un exemple de recherches :L’éditeur peut constater les modalités d’emprunts de ses textes par ce moteur de réponses, en comparant l’article créé à partir d’un de ses articles scrapés. Exemple sur une recherche à partir du contenu d’un article de niche, sur lequel il y aura peu de contenus d’agence ou de confrères:
Article originel
https://www.leparisien.fr/paris-75/monoprix-ouvre-son-premier-magasin-de-decoration-a-paris-12-07-2023-S4R3WCCWNZCLZILLSB6XOUZH3Y.php
question: Monoprix ouvre un magasin deco design ? La réponse de You.com
Stats sur Botscorner
Les stats de you.com commencent à se remarquer, avec quelques milliers de pages par jour sur les sites branchés sur le service. [...]Lire la suite…

Le Botservatoire , le bulletin des crawlers commerciaux, n°07 – Ubermetrics Unicepta21 septembre 2023Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs radio, TV, presse online & print.une catégorie intermédiaire de bots, , plus discrète, mais qui crawle massivement les sites : les bots commerciaux . ils opèrent pour les activités de veille, permettent d’élaborer des stats, des analyses, des résumés, fournissent les IA, revendent les bases à des tiers…
Portrait Robot de Ubermetrics , filiale d’Unicepta, une société de mediamonitoring .
Ubermetrics propose un service de monitoring d’informations collectées mondialement sur les sites de presse :
Ubermetrics is the leading Content Intelligence platform for communication experts. Its AI-driven media monitoring and analytics technology processes over 50,000 articles per minute from over 460 million global sources across all media types (print, online, social, TV & Radio).
https://www.adwired.ch/company/partner/
Le service s’adresse aux entreprises.
plus de 550 clients font confiance à notre expertise et à nos solutions. Parmi eux, on compte deux tiers des entreprises du DAX-40, des grands noms du CAC-40 et du SBF 120, ainsi que de nombreuses autres entreprises multinationales
https://www.unicepta.com/fr/a-propos-dunicepta/societe.html
Clients : Airbus, Adidas, Bayer, Bosch, BMW, BritishAirways, Fifa, Mercedes, Stellantis, Lenovo, Tiktok, Virgin, Siemens…
IA Comme beaucoup d’acteurs du mediamonitoring désormais, Unicepta annonce un service de curation de contenus augmenté d’IA : « Grâce à une technologie d’exploration alimentée par l’IA, UNICEPTA capture le contenu pertinent de 460 millions de sources médiatiques, partout dans le monde : Agences de Presse, presse écrite, presse en ligne, médias audiovisuels et sociaux, médias nationaux, locaux ou régionaux, mais aussi des publications plus confidentielles ou grand public. »
Fourniture de résumés « de haute qualité éditoriale vous offrant l’essentiel en un coup d’œil. Vos informations qui comptent, reprises dans un format concis. Nos résumés éditoriaux multilingues et cross-média sont compilés et rédigés par des rédacteurs seniors expérimentés, issus d’équipes spécialisées dans votre secteur d’activité ».
Des projets en cours : “We have been closely involved in the AI research landscape since 2011 – as a participant in expert discussions with the BMWi and BMBF as well as with the Federal Chancellor, as a member of the German AI Association”
Les projets aboutis : qurator.ai , evalitech , Plass
obéir à robots.txt n’est pas une option qui semble avoir été retenue par Ubermetrics. Sur Botscorner, on le voit bien passer sur cette page Robots.txt publiée à la racine des sites des éditeurs de presse, et dédiée à la gestion des bots. Mais son scraper passe sur les articles malgré un refus sur « ubermetric » chez un éditeur.
Unicepta, c’est aussi Adwired « Adwired AG – the specialist for media and brand analysis – enters into a distribution partnership with Dow Jones / Factiva. As a Dow Jones reseller, Adwired may license approximately 5,000 international Paywall-protected media sources directly to its customers”
Stats sur Botscorner.
Les stats de Ubermetrics sur les sites de presse branchés sur le service sont impressionnantes : jusqu’à 500 000 requêtes sur 24 heures. [...]Lire la suite…

Le Botservatoire , le bulletin des crawlers commerciaux, n°06 – Les sites qui copient12 septembre 2023L’info, c’est l’éditeur qui la produit, c’est le bot qui la publie !
voir les précédents Botservatoires
Les bots ne se contentent pas de constituer des bases pour les revendre aux IA ni de les structurer en offres, notamment de media monitoring. On assiste désormais à la création de nombreux sites d’infos dont les contenus sont rédigés à partir des articles de presse collectés en ligne.
Les bots commencent généralement par indexer (crawler) les infos de création ou de mise à jour des articles ou photos (sitemap, RSS, têtes de rubriques), puis vont chercher (scraper) les articles qui les intéressent.
Pour cette activité, les bots prennent beaucoup moins d’articles que les entreprises de big data ou de media monitoring qui en récupèrent des milliers par jour. Pour de la republication, quelques articles par jour et par éditeur suffisent pour faire vivre un site de news. Le modèle économique est généralement la publicité.
S’il est rare de les voir remonter sur Google, certains de ces sites proposent de s’abonner à leur newsletter ou à leur fils Telegram, sur lesquels ils communiquent sur leurs articles.
Si l’article complet est disponible sur le site originel, il sera publié en entier (avec un lien vers la source, devenu inutile).
Par exemple : Article d’origine :
Article identique, mais complet, republié sur un autre site:
La nouveauté ? L’ l’IA facilite de nombreux services parmi lesquels le résumé, la revue de presse citant un ou plusieurs articles, la traduction à la volée qui permet avec un seul article d’en publier plusieurs dans toutes les langues…
Le Figaro :
Et son équivalent, qui correspond au résultat donné par un service en ligne de traduction automatique :
On peut même être gratifié d’un avertissement, qui explique la démarche. Près d’une reprise d’un article, on peut lire :
AVIS IMPORTANT
Tous les articles sont traduits de la source originale. Nous exploitons un service de traduction pour aider les anglophones en France à comprendre ce qui se passe dans toute la France.
Tout le contenu et les photos sont la propriété de la source originale. Chaque article a un lien vers la source originale au bas de l’article. Nous ne stockons aucune image de la source d’origine sur notre serveur (…)
Si vous souhaitez qu’un élément soit supprimé, vous pouvez nous contacter avec l’URL et la preuve des droits de propriété pour supprimer tout élément de notre système.
Evidemment, le site n’a pas de directeur de publication, et la page contact n’existe pas.
Ces sites de « news » ont généralement des maquettes assez sommaires, avec de nombreuses rubriques (alimenter toutes ces rubriques nécessiterait une vraie rédaction, qui semble assez absente).
Nous remontons sur Botscorner une soixantaine de sites qui publient des articles récupérés sur les sites de news.
Attention :
à ne pas mettre l’intégralité d’un article dans le flux RSS ,
à ne pas rendre disponible un article par le code source quand il est soumis à un paywall. [...]Lire la suite…

Le Botservatoire , le bulletin des crawlers commerciaux, n°05 – Semrush-Prowly16 juin 2023Comment une société spécialisée en SEO peut-elle étendre ses services à ses nombreux clients : les données collectées sur le net pourraient-elles s’étendre à d’autres usages ?
Dans le précédent Botservatoire, on a vu que des sociétés à but non lucratif pouvaient nourrir gracieusement des IA avec les données des éditeurs de presse (CommonCrawl.org pour OpenAI-ChatGPT).
Portrait Robot de : Semrush.com et de sa filiale Prowly.com
SEMrush, données financières : CA 170,7M$ , valorisation de la société 2,4B$ (source:growjo.com)
Un service de Search Engine Optimization permet de suivre le positionnement de son site sur le web. Semrush met en avant un service très performant. Il crawle votre site et les sites concurrents. Il vous indique alors ce que vos concurrents font mieux que vous, et surtout comment améliorer votre classement par rapport à eux.
Semrush a vite augmenté son offre de services :
plateforme agence relations Publiques ,
analyse des interactions sur les réseaux sociaux ,
des publicités Display des concurrents ,
mais aussi : agence de création de contenus ,
et Media Monitoring (suivi des mentions presse)
La création d’articles, quel que soit le sujet, est évidemment garantie optimisée pour les moteurs de recherches. Des options permettent de reformuler un texte copié pour éviter le plagiat , en comparant dans une base de textes. Et une IA peut même générer des textes.
Enfin, le service de media monitoring est assuré par une société achetée en 2020 par Semrush : Prowly.
Pour un prix annoncé inférieur à ceux de Cision ou Meltwater, Prowly remontera les mentions trouvées dans la presse
Avis : On comprend bien l’intérêt du client de Semrush de le laisser crawler son propre site, on comprend moins bien celui du site concurrent, s’il n’est pas lui-même client de Semrush. En effet, il va donner gratuitement des informations qui permettront à ses rivaux de lui passer devant sur Google. Quelques éditeurs ont d’ailleurs décidé de bloquer le crawl de sociétés offrant ce type de services, en attendant qu’une licence couvrant l’utilisation de leurs contenus soit signée.
Le crawler de Semrush collecte des datas en permanence, jusqu’à 240 000 requêtes par jour, visibles sur les sites branchés sur le service. On en compte 20 000 de plus sur un crawl attribué à Prowly, qui ne met pas de user agent éponyme.
statistiques du bot Semrush sur des sites de presse Français [...]Lire la suite…

Le Botservatoire , le bulletin des crawlers commerciaux, n°04 – CommonCrawl7 juin 2023L’industrie du big data vend les articles de presse, ou les données extraites de ces articles, à zéro euro. Cela signifie-t-il qu’il n’y a pas de modèle économique sur ce marché pour un site de presse ?Dans le précédent Botservatoire on a vu que des sociétés commerciales proposent leurs services à un prix très bas. Chez Webzio, l’article est à 0,0002€, ce qui laisse imaginer la part réservée au droit d’auteur.
Comment construire un modèle économique ? En demandant à ces sociétés commerciales de tenir compte, dans leur tarification, de la rémunération des éléments extraits des sites de presse. Aujourd’hui, ces services ne facturent que leur technologie. Mais sans les éléments extraits des sites de presse et relevant du droit d’auteur, il n’y aurait pas de service.Mais le big data encore moins cher existe !
Portrait Robot de CommonCrawl.org
Des sociétés à but non lucratif crawlent également les sites de presse.CommonCrawl est un service gratuit mettant à disposition sept années d’archives. Les données sont disponibles gratuitement pour la recherche, et payées au bon vouloir des utilisateurs, par des donations.
CommonCrawl propose un accès aux archives, dans plus de 40 langues. Cela permet aux chercheurs du public, comme du privé, d’entraîner leurs IA.
CommonCrawl est une organisation à but non lucratif. A ce titre, une société qui souhaite utiliser des articles de presse pour entraîner une IA, peut travailler sur les bases offertes et financer l’activité de CC.org en bénéficiant de réductions d’impôts. Ainsi, Meta pour son IA appelée LLaMA, ou OpenAI pour ChatGPT, ont pu, comme des centaines d’autres, utiliser ces données disponibles issues de CC.org ou Wikipedia :
Source : medium.com
Ainsi, un crawl gratuit sans modèle économique peut générer des services commerciaux très rentables. ChatGPT a désormais un investisseur de choix avec Microsoft, et se trouve incorporé à la recherche Bing avec une version améliorée.
Le crawler de CommonCrawl collecte des datas en permanence, et à plus forte dose une semaine par mois (entre 5000 et 25000 requêtes par jour).En effet, l’offre de CC.org consiste à proposer une base d’articles permettant d’agréger des connaissances pour des IA. Cela diffère des offres big data utilisées par des sociétés de media monitoring et e-réputation, qui crawlent plus massivement car elles ont besoin des dernières informations dès leur publication. [...]Lire la suite…
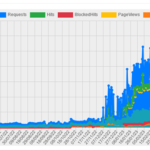
Le Botservatoire , le bulletin des crawlers commerciaux, n°03 – Webzio11 mai 2023Par BotsCorner.com
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs de presse. Une catégorie de bots crawle massivement, mais discrètement, les sites : les bots commerciaux. Ils opèrent pour les activités de veille, permettent d’élaborer des stats, des analyses, des résumés. Ils fournissent en contenus les IA, revendent les bases à des tiers…
Portrait-robot de Webz.io , société de collecte et revente Big data
Webz.io propose un service de collecte et de mise en forme de données récoltées sur le web.Tous les sites d’informations les plus pertinents sont crawlés, Webz.io déclare collecter 2,5 millions d’articles chaque jour sur 180 000 sites d’informations. Ce crawl permanent permet de fournir des résultats en quasi temps réel. De plus, Webz.io propose un accès aux archives depuis 2008.
CA estimé: 4M$
1. Les clients du service : Webz.io annonce travailler pour SalesForce, IBM, Datarobot , Sprinklr, Kantar , Brandwatch, Meltwater , Mention …
2. Le bot passe sur le fichier « robots.txt » mis en place par les éditeurs, mais ne semble pas en respecter toutes les interdictions mentionnées (l’observation de ces instructions n’est pas obligatoire).
3. La valeur : A notre connaissance, Webz.io n’envisage pas d’intégrer les droits d’auteur dans ses formules tarifaires.
Les tarifs ne sont pas publics, mais selon cette page c’est en moyenne 200€/mois pour un crawl assez massif.
Les datas archives sont chiffrées en fonction de l’abonnement du client à Webz.io. Le premier prix, très attractif, est de 0.0002€ par article.
4. La recommandation : en l’absence d’accord, bloquer.
Ce scraping ne génère pas de visites : il peut même concurrencer des infomédiaires ayant signé des accords pour rémunérer les éditeurs. De surcroît, le tarif très bas de ce service institue les sites d’informations comme sources de matière première gratuite.
5. Stats sur Botscorner.
Les stats de Webz.io sur les sites d’informations branchés sur le service proposé par le CFC montrent jusqu’à 130 000 requêtes en 24 heures.
Statistiques passage webz.io sur le service Botscorner [...]Lire la suite…
Le Botservatoire , le bulletin des crawlers commerciaux, n°02 – Gnowit4 mai 2023Par BotsCorner.comTous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs de presse. Une catégorie de bots crawle massivement, mais discrètement, les sites : les bots commerciaux. Ils opèrent pour les activités de veille, permettent d’élaborer des stats, des analyses, des résumés. Ils fournissent en contenus les IA, revendent les bases à des tiers…
Portrait-Robot de GNOWIT.COM , société de media monitoring.
Gnowit propose un service d’alerte et d’analyses à partir de données crawlées sur plus de deux millions de sources (des sites de presse et des sites institutionnels), pour des prix allant de 200 à 2000 $Can par mois. CA estimé: moins de 2M$ (estimation growjo.com)
Le service s’adresse aux entreprises et aux administrations… Gnowit « capture » les informations dans les quinze minutes qui suivent leur publication, et propose à ses clients B2B d’effectuer des recherches sur le « full-text »
L’option : la sélection d’articles par des humains. Ce service peut inclure du contenu derrière le paywall, du contenu de niche ou « difficile d’accès ». (https://www.gnowit.com/pricing/ rubrique « add-ons available »).Compter 1000$Can/mois en plus pour 5 thématiques.
3. Le crawl avec user-agent Gnowit provient de dizaines d’hébergeurs, de centaines d’IPs qui changent régulièrement. Cela oblige l’éditeur à un suivi contraignant, s’il était tenté par un blocage des téléchargements de ses données.
Par ailleurs, sur les éditeurs installés sur nos services, le bot Gnowit ne passe pas sur le fichier « robots.txt » (robots.txt indique aux bots si leur crawl est autorisé sur tout ou partie du site).
La valeur : A notre connaissance, Gnowit ne demande pas d’autorisation avant de faire passer ses robots sur les sites de presse, et n’envisage pas d’intégrer les droits d’auteur dans ses formules tarifaires.FAQ de Gnowit: pour rester en accord avec les lois sur le copyright, Gnowit délivre le lien vers le document original, avec un extrait du texte. Mais les recherches se font sur le texte entier, hébergé chez Gnowit. Gnowit propose l’export du « full text » pour l’abonnement « Entreprise » dans le cadre d’un contrat qui assure le client que l’usage entre dans le cadre des exceptions prévues dans les lois de la plupart des juridictions concernées.
FAQ Gnowit
La recommandation : en l’absence d’accord, bloquer.Les infomédiaires abonnent des clients B2B à des contenus issus de sources de presse, ce qui nécessite un accord préalable. Nombre d’entre eux ont déjà signé, en direct ou par l’intermédiaire de leurs mandataires, des accords encadrant des utilisations identiques.
Stats sur Botscorner.Les stats de Gnowit sur les sites d’informations branchés sur le service proposé par le CFC vont jusqu’à 110 000 requêtes par jour. La semaine prochaine… Webzio
Statistiques passage Gnowit sur le service Botscorner.com [...]Lire la suite…
Le Botservatoire, une newsletter des crawlers commerciaux – n01 Diffbot4 mai 2023Par BotsCorner.com
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs de presse.
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs de presse. Certains bots sont des partenaires des éditeurs (Googlebot, Bingbot, publicité…) , d’autres attaquent les sites (ddos, spam, …) et nécessitent un blocage immédiat.
Il reste une catégorie intermédiaire, plus discrète, mais qui crawle massivement les sites : les bots commerciaux . ils opèrent pour les opérateurs d’activités de veille, ils permettent d’élaborer des statistiques, des analyses, des résumés, fournissent les IA, revendent « leurs » bases à des tiers…
Analyse d’aujourd’hui : DIFFBOT.COM , un grossiste data.
Diffbot propose un service de big data, crawlés (indexés) et scrapés (téléchargés) à des prix défiant toute concurrence.
1. Le service s’adresse aux entreprises, prestataires de panoramas, analystes, statisticiens.. Diffbot annonce travailler pour Meltwater, Cision, Factset, Dowjones, …cela consiste en un téléchargement de données de sites différents, qui ont donc des structures différentes, pour constituer une base d’articles structurée exploitable.
2. Le téléchargement est quotidien et massif, mais il est effectué sous les radars, donc sans blocage :
–obéir à robots.txt est en option dans une case à cocher ,
Diffbot propose à ses clients de choisir de se conformer, ou pas, au fichier robots.txt
-il propose des proxies, des IPs jetables qui permettent de diluer et invisibiliser un crawl massif : « No More Blocked Crawls. Utilize our reserved fleet of proxy IPs, optionally upgrade to gain access to tens of thousands of unique IPs for truly diversified crawling or region/country-specific extraction”.
-il propose également de crawler « derrière le login »
vidéos en ligne détaillant les offres Diffbot
3. les données prélevées sur un site de presse sont donc revendues à la page, sans nécessiter l’accord préalable de l’éditeur, ni tenir compte des droits d’auteur: à $0.0009/page! Le modèle économique de Diffbot n’intègre pas de rétrocession pour les ayants droit
“The number of credits you need will depend on your use case and volume. Extracting a single web page will use 1 credit, so scraping 100,000 pages monthly will require 100,000 credits per month. (..) if you use 1,500,000 credits in a month on the Plus plan, your billed amount that month will be $899 (Plan Base) + 500,000 x $0.0009/credit”.
4. recommandation: bloquer tant qu’il n’y a pas d’accord.
Les bots qui font du big data ont un impact sur le modèle économique des éditeurs et de leurs mandataires. En fournissant à prix très bas des grands volumes de contenus à de nombreux tiers pour toutes exploitations, ils facilitent l’utilisation massive des contenus des sites sans contrepartie ni autorisation.
5. stats sur Botscorner.
Les stats de Diffbot sur les journaux branchés sur le service ORRC proposé par le CFC sont massives : jusqu’à 1 800 000 requêtes sur 24h .
Statistiques passage Diffbot sur le service Botscorner.com
La semaine prochaine : webzio [...]Lire la suite…