
Comment une société spécialisée en SEO peut-elle étendre ses services à ses nombreux clients : les données collectées sur le net pourraient-elles s’étendre à d’autres usages ?

Dans le précédent Botservatoire, on a vu que des sociétés à but non lucratif pouvaient nourrir gracieusement des IA avec les données des éditeurs de presse (CommonCrawl.org pour OpenAI-ChatGPT).
Portrait Robot de : Semrush.com et de sa filiale Prowly.com
SEMrush, données financières : CA 170,7M$ , valorisation de la société 2,4B$ (source:growjo.com)
Un service de Search Engine Optimization permet de suivre le positionnement de son site sur le web. Semrush met en avant un service très performant. Il crawle votre site et les sites concurrents. Il vous indique alors ce que vos concurrents font mieux que vous, et surtout comment améliorer votre classement par rapport à eux.
Semrush a vite augmenté son offre de services :
plateforme agence relations Publiques ,
analyse des interactions sur les réseaux sociaux ,
des publicités Display des concurrents ,
mais aussi : agence de création de contenus ,
et Media Monitoring (suivi des mentions presse)
La création d’articles, quel que soit le sujet, est évidemment garantie optimisée pour les moteurs de recherches. Des options permettent de reformuler un texte copié pour éviter le plagiat , en comparant dans une base de textes. Et une IA peut même générer des textes.
Enfin, le service de media monitoring est assuré par une société achetée en 2020 par Semrush : Prowly.
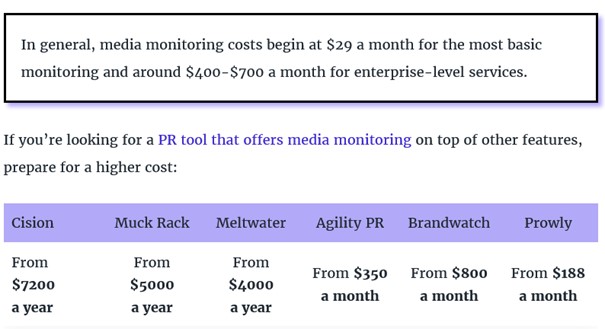
Pour un prix annoncé inférieur à ceux de Cision ou Meltwater, Prowly remontera les mentions trouvées dans la presse
Avis : On comprend bien l’intérêt du client de Semrush de le laisser crawler son propre site, on comprend moins bien celui du site concurrent, s’il n’est pas lui-même client de Semrush. En effet, il va donner gratuitement des informations qui permettront à ses rivaux de lui passer devant sur Google. Quelques éditeurs ont d’ailleurs décidé de bloquer le crawl de sociétés offrant ce type de services, en attendant qu’une licence couvrant l’utilisation de leurs contenus soit signée.
Le crawler de Semrush collecte des datas en permanence, jusqu’à 240 000 requêtes par jour, visibles sur les sites branchés sur le service. On en compte 20 000 de plus sur un crawl attribué à Prowly, qui ne met pas de user agent éponyme.
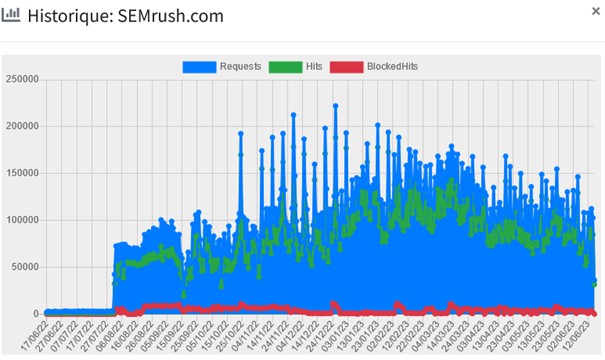
statistiques du bot Semrush sur des sites de presse Français