L’industrie du big data vend les articles de presse, ou les données extraites de ces articles, à zéro euro. Cela signifie-t-il qu’il n’y a pas de modèle économique sur ce marché pour un site de presse ?
Dans le précédent Botservatoire on a vu que des sociétés commerciales proposent leurs services à un prix très bas. Chez Webzio, l’article est à 0,0002€, ce qui laisse imaginer la part réservée au droit d’auteur.
Comment construire un modèle économique ? En demandant à ces sociétés commerciales de tenir compte, dans leur tarification, de la rémunération des éléments extraits des sites de presse. Aujourd’hui, ces services ne facturent que leur technologie. Mais sans les éléments extraits des sites de presse et relevant du droit d’auteur, il n’y aurait pas de service.
Mais le big data encore moins cher existe !
Portrait Robot de CommonCrawl.org
Des sociétés à but non lucratif crawlent également les sites de presse.
CommonCrawl est un service gratuit mettant à disposition sept années d’archives. Les données sont disponibles gratuitement pour la recherche, et payées au bon vouloir des utilisateurs, par des donations.

CommonCrawl propose un accès aux archives, dans plus de 40 langues. Cela permet aux chercheurs du public, comme du privé, d’entraîner leurs IA.

CommonCrawl est une organisation à but non lucratif. A ce titre, une société qui souhaite utiliser des articles de presse pour entraîner une IA, peut travailler sur les bases offertes et financer l’activité de CC.org en bénéficiant de réductions d’impôts. Ainsi, Meta pour son IA appelée LLaMA, ou OpenAI pour ChatGPT, ont pu, comme des centaines d’autres, utiliser ces données disponibles issues de CC.org ou Wikipedia :
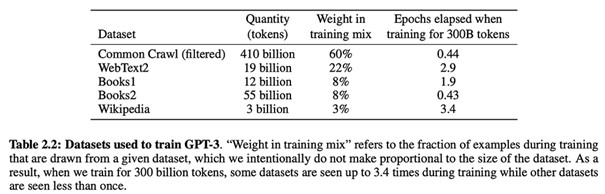
Source : medium.com
Ainsi, un crawl gratuit sans modèle économique peut générer des services commerciaux très rentables. ChatGPT a désormais un investisseur de choix avec Microsoft, et se trouve incorporé à la recherche Bing avec une version améliorée.
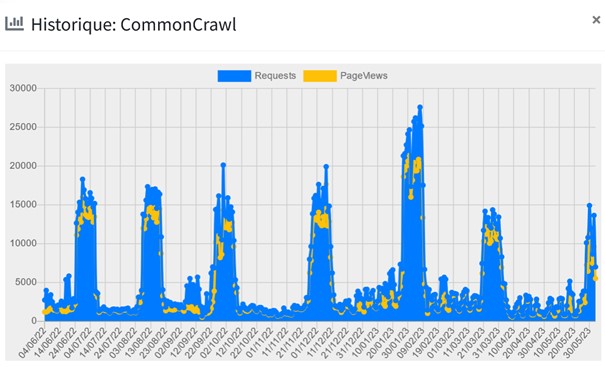
Le crawler de CommonCrawl collecte des datas en permanence, et à plus forte dose une semaine par mois (entre 5000 et 25000 requêtes par jour).
En effet, l’offre de CC.org consiste à proposer une base d’articles permettant d’agréger des connaissances pour des IA. Cela diffère des offres big data utilisées par des sociétés de media monitoring et e-réputation, qui crawlent plus massivement car elles ont besoin des dernières informations dès leur publication.