Par BotsCorner.com
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs de presse. Une catégorie de bots crawle massivement, mais discrètement, les sites : les bots commerciaux. Ils opèrent pour les activités de veille, permettent d’élaborer des stats, des analyses, des résumés. Ils fournissent en contenus les IA, revendent les bases à des tiers…
Portrait-robot de Webz.io , société de collecte et revente Big data
Webz.io propose un service de collecte et de mise en forme de données récoltées sur le web.
Tous les sites d’informations les plus pertinents sont crawlés, Webz.io déclare collecter 2,5 millions d’articles chaque jour sur 180 000 sites d’informations. Ce crawl permanent permet de fournir des résultats en quasi temps réel. De plus, Webz.io propose un accès aux archives depuis 2008.
1. Les clients du service : Webz.io annonce travailler pour SalesForce, IBM, Datarobot , Sprinklr, Kantar , Brandwatch, Meltwater , Mention …
2. Le bot passe sur le fichier « robots.txt » mis en place par les éditeurs, mais ne semble pas en respecter toutes les interdictions mentionnées (l’observation de ces instructions n’est pas obligatoire).
3. La valeur : A notre connaissance, Webz.io n’envisage pas d’intégrer les droits d’auteur dans ses formules tarifaires.
Les tarifs ne sont pas publics, mais selon cette page c’est en moyenne 200€/mois pour un crawl assez massif.
Les datas archives sont chiffrées en fonction de l’abonnement du client à Webz.io. Le premier prix, très attractif, est de 0.0002€ par article.
4. La recommandation : en l’absence d’accord, bloquer.
Ce scraping ne génère pas de visites : il peut même concurrencer des infomédiaires ayant signé des accords pour rémunérer les éditeurs. De surcroît, le tarif très bas de ce service institue les sites d’informations comme sources de matière première gratuite.
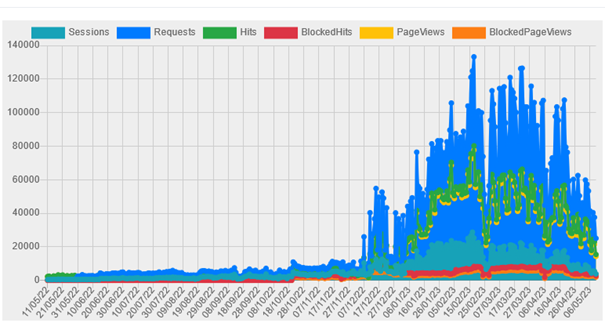
5. Stats sur Botscorner.
Les stats de Webz.io sur les sites d’informations branchés sur le service proposé par le CFC montrent jusqu’à 130 000 requêtes en 24 heures.