
Par BotsCorner.com
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs de presse.
Tous les jours, des centaines de crawlers collectent des données sur les sites des éditeurs de presse. Certains bots sont des partenaires des éditeurs (Googlebot, Bingbot, publicité…) , d’autres attaquent les sites (ddos, spam, …) et nécessitent un blocage immédiat.
Il reste une catégorie intermédiaire, plus discrète, mais qui crawle massivement les sites : les bots commerciaux . ils opèrent pour les opérateurs d’activités de veille, ils permettent d’élaborer des statistiques, des analyses, des résumés, fournissent les IA, revendent « leurs » bases à des tiers…
Analyse d’aujourd’hui : DIFFBOT.COM , un grossiste data.
Diffbot propose un service de big data, crawlés (indexés) et scrapés (téléchargés) à des prix défiant toute concurrence.
1. Le service s’adresse aux entreprises, prestataires de panoramas, analystes, statisticiens.. Diffbot annonce travailler pour Meltwater, Cision, Factset, Dowjones, …cela consiste en un téléchargement de données de sites différents, qui ont donc des structures différentes, pour constituer une base d’articles structurée exploitable.
2. Le téléchargement est quotidien et massif, mais il est effectué sous les radars, donc sans blocage :
–obéir à robots.txt est en option dans une case à cocher ,

-il propose des proxies, des IPs jetables qui permettent de diluer et invisibiliser un crawl massif : « No More Blocked Crawls. Utilize our reserved fleet of proxy IPs, optionally upgrade to gain access to tens of thousands of unique IPs for truly diversified crawling or region/country-specific extraction”.
-il propose également de crawler « derrière le login »

3. les données prélevées sur un site de presse sont donc revendues à la page, sans nécessiter l’accord préalable de l’éditeur, ni tenir compte des droits d’auteur: à $0.0009/page! Le modèle économique de Diffbot n’intègre pas de rétrocession pour les ayants droit
“The number of credits you need will depend on your use case and volume. Extracting a single web page will use 1 credit, so scraping 100,000 pages monthly will require 100,000 credits per month. (..) if you use 1,500,000 credits in a month on the Plus plan, your billed amount that month will be $899 (Plan Base) + 500,000 x $0.0009/credit”.
4. recommandation: bloquer tant qu’il n’y a pas d’accord.
Les bots qui font du big data ont un impact sur le modèle économique des éditeurs et de leurs mandataires. En fournissant à prix très bas des grands volumes de contenus à de nombreux tiers pour toutes exploitations, ils facilitent l’utilisation massive des contenus des sites sans contrepartie ni autorisation.
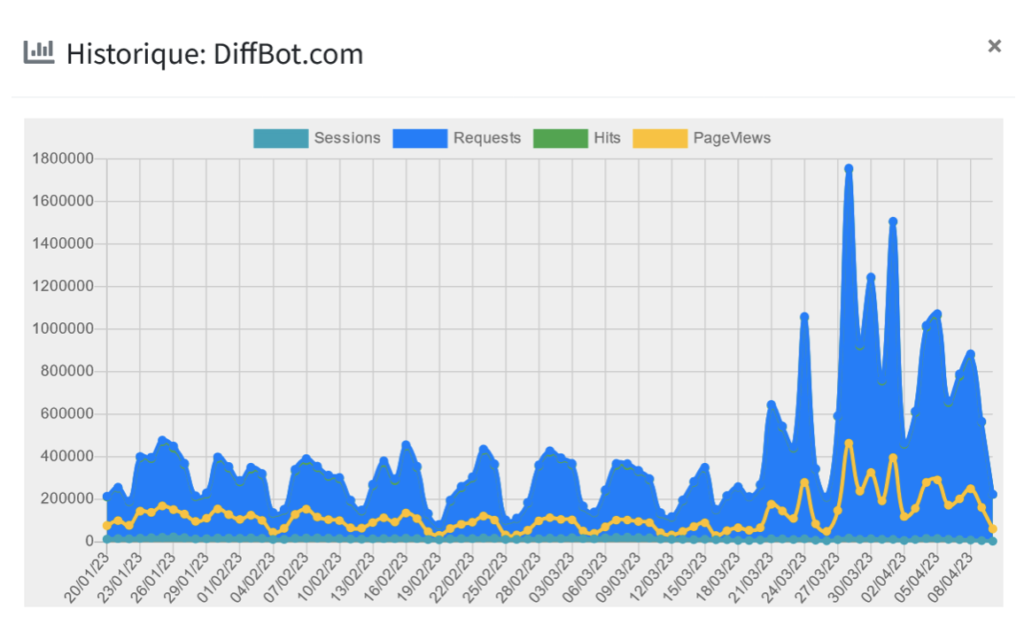
5. stats sur Botscorner.
Les stats de Diffbot sur les journaux branchés sur le service ORRC proposé par le CFC sont massives : jusqu’à 1 800 000 requêtes sur 24h .
La semaine prochaine : webzio